Does Bayesian statistical analysis involve stronger assumptions compared to frequentist statistical analysis? It is commonly believed that the answer is yes because frequentist analysis makes assumptions about the likelihood while Bayesian analysis requires assumptions on both the likelihood and the prior. Since priors are absent from frequentist analysis, it seems reasonable to say that Bayesian analysis needs more assumptions compared to frequentist analysis. Quite a few statisticians distrust modeling assumptions on the grounds that they are fundamentally unverifiable and these statisticians are much more sceptical about Bayesian methods compared to frequentist ones.
I held similar views until not too long ago but have realized recently that the nature of assumptions underlying frequentist and Bayesian analyses is quite different and it is not at all clear to me anymore that frequentist analysis indeed makes fewer assumptions. In fact, from the likelihood standpoint, Bayesian analysis makes much fewer assumptions compared to frequentist analysis. Specifically, in Bayesian analysis, one needs to model only the probability of observing the given dataset at hand conditional on the unknown parameter while in frequentist analysis, one typically needs to model, for every possible imaginary dataset, the probability of observing that dataset. I will try to illustrate this here using the following elementary problem in statistical inference that is surely familiar to every statistics student.
Problem: Suppose a scientist makes 

Standard frequentist and Bayesian approaches to this problem are described below and they lead to identical solutions which allows for a transparent comparison of the assumptions underlying the two approaches. I will assume below that all involved random variables have densities.
Let me start with a detailed description of the standard frequentist approach. The observed dataset here consists of the 







Freq-Step 1: The observed values 

Freq-Step 2: 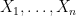

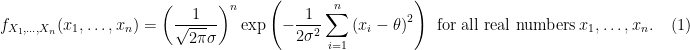
The above assumption describes the probability of obtaining every possible imaginary dataset in the sample space.
Freq-Step 3: Under assumption (1), it is a well-known mathematical fact that 


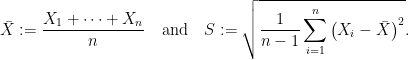
Freq-Step 4: Because of the distributional result of Freq-Step 3,
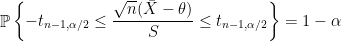

where 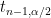

![\displaystyle \left[\bar{X}-t_{n-1, \alpha/2} \frac{S}{\sqrt{n}}, \bar{X} + t_{n-1, \alpha/2} \frac{S}{\sqrt{n}} \right] ~~ \text{with probability}~ 1-\alpha. \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B%5Cbar%7BX%7D-t_%7Bn-1%2C+%5Calpha%2F2%7D+%5Cfrac%7BS%7D%7B%5Csqrt%7Bn%7D%7D%2C+%5Cbar%7BX%7D+%2B+t_%7Bn-1%2C+%5Calpha%2F2%7D+%5Cfrac%7BS%7D%7B%5Csqrt%7Bn%7D%7D+%5Cright%5D+%7E%7E+%5Ctext%7Bwith+probability%7D%7E+1-%5Calpha.+%5C+%5C+%5C+%5C+%5C+%282%29&bg=FFFFFF&fg=000000&s=0&c=20201002)
Freq-Step 5: The observed values corresponding to ![\displaystyle [31.35 - t_{5, \alpha/2} (2.238), 31.35 + t_{5, \alpha/2} (2.238)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B31.35+-+t_%7B5%2C+%5Calpha%2F2%7D+%282.238%29%2C+31.35+%2B+t_%7B5%2C+%5Calpha%2F2%7D+%282.238%29%5D&bg=FFFFFF&fg=000000&s=0&c=20201002)



![{[25.598, 37.102]}](https://s0.wp.com/latex.php?latex=%7B%5B25.598%2C+37.102%5D%7D&bg=FFFFFF&fg=000000&s=0&c=20201002)
So the frequentist approach required a specification of the sample space and the precise assumption (1) of the probability of observing every possible imaginary dataset in the sample space. If we only make the assumption (1) for a subset of datasets in the sample space, the distributional fact in Freq-Step 3 will no longer hold. An alternative frequentist approach based on asymptotics to this problem would make, instead of (1), the assumption that

for some density function 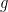

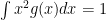

Let us now look at the standard Bayesian approach before comparing the two approaches.
Bayes-Step 1: The observed values 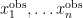

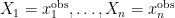

Bayes rule is applied to give

where the 



Bayes-Step 2: For the likelihood model, a parameter 

It is assumed that
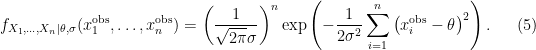

for all 
Bayes-Step 3: Plugging in (6) and (5) in (4), we get

One can pull out the term involving

where

One can check with the formula for the density of the

having the student
Bayes-Step 4: Because of the distributional result in Bayes-Step 3,
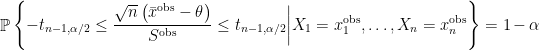
which is equivalent to saying that, conditional on
![\displaystyle \left[\bar{x}^{\text{obs}}-t_{n-1, \alpha/2} \frac{s^{\text{obs}}}{\sqrt{n}}, \bar{x}^{\text{obs}} + t_{n-1, \alpha/2} \frac{s^{\text{obs}}}{\sqrt{n}} \right] ~~ \text{ with probability} ~ 1 - \alpha. \ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B%5Cbar%7Bx%7D%5E%7B%5Ctext%7Bobs%7D%7D-t_%7Bn-1%2C+%5Calpha%2F2%7D+%5Cfrac%7Bs%5E%7B%5Ctext%7Bobs%7D%7D%7D%7B%5Csqrt%7Bn%7D%7D%2C+%5Cbar%7Bx%7D%5E%7B%5Ctext%7Bobs%7D%7D+%2B+t_%7Bn-1%2C+%5Calpha%2F2%7D+%5Cfrac%7Bs%5E%7B%5Ctext%7Bobs%7D%7D%7D%7B%5Csqrt%7Bn%7D%7D+%5Cright%5D+%7E%7E+%5Ctext%7B+with+probability%7D+%7E+1+-+%5Calpha.+%5C+%5C+%5C+%5C+%5C+%287%29&bg=FFFFFF&fg=000000&s=0&c=20201002)
Bayes-Step 5: The observed values corresponding to
as the
The Bayes analysis which leads to identical answers as the frequentist analysis relies on the assumption (6) for the prior and the assumption (5) for the likelihood. Let us now compare these with the assumptions (1) (and (3)) underlying frequentist analysis:
- Priors: Bayesian analysis uses the assumption (6) on the prior densities and, of course, there are no such assumptions in frequentist analysis. In this particular case, the prior assumptions are reasonable and principled arguments (based on invariant transformations) exist to justify them as a valid mathematical representation of the state of complete ignorance on part of the scientist/data analyst about
- Likelihood: The frequentist likelihood assumption is (1) while the Bayesian likelihood assumption is (5). Clearly (1) is much stronger than (5) as the former requires equality at all
This should be avoided as it refers to (1) while the actual Bayesian assumption is the much weaker (5). As I already mentioned, the
- More on likelihood: Let us now compare the alternative frequentist likelihood assumption (3) with (5). These cannot be directly compared but one can still note that (3) is assumed for all
to
and (3) is a very strong assumption (although it is weaker than (1)) when
- As functions of
Strong assumptions are usually easy to invalidate and (1) can be invalidated easily when
An interesting aspect of the specific problem considered here is that both the frequentist and Bayesian approaches lead to the same answer. Specifically, both approaches assert that ![{\theta \in [25.598, 37.102]}](https://s0.wp.com/latex.php?latex=%7B%5Ctheta+%5Cin+%5B25.598%2C+37.102%5D%7D&bg=FFFFFF&fg=000000&s=0&c=20201002)
![\displaystyle \theta \in \left[\bar{X}-t_{n-1, \alpha/2} \frac{S}{\sqrt{n}}, \bar{X} + t_{n-1, \alpha/2} \frac{S}{\sqrt{n}} \right]. \ \ \ \ \](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctheta+%5Cin+%5Cleft%5B%5Cbar%7BX%7D-t_%7Bn-1%2C+%5Calpha%2F2%7D+%5Cfrac%7BS%7D%7B%5Csqrt%7Bn%7D%7D%2C+%5Cbar%7BX%7D+%2B+t_%7Bn-1%2C+%5Calpha%2F2%7D+%5Cfrac%7BS%7D%7B%5Csqrt%7Bn%7D%7D+%5Cright%5D.+%5C+%5C+%5C+%5C+%5C+&bg=FFFFFF&fg=000000&s=0&c=20201002)
This statement (written in terms of the random variables
To summarize this post, frequentist methods make much more stringent assumptions on the probability of observing data compared to Bayesian methods. On the other hand, Bayesian methods involve prior assumptions which frequentist methods have no need for. Which analysis are you more comfortable with?
