My first post is about a beautiful hypothesis testing inequality due to Le Cam [1, Chapter 16, Section 4]. Here is the setting. There is an unknown distribution 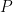 on which we have two hypotheses. The first hypothesis is
on which we have two hypotheses. The first hypothesis is  and the second is
and the second is 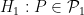 where
where 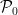 and
and  denote classes of probability measures. Given i.i.d data
denote classes of probability measures. Given i.i.d data  from , the goal is to figure out which of the two hypothesis is the right one.
from , the goal is to figure out which of the two hypothesis is the right one.
As one gets more and more data points i.e., as  increases, this problem intuitively should get easier. Le Cam’s inequality quantifies this by asserting that the error in this hypothesis testing problem decreases exponentially in . The precise statement and a proof sketch of this inequality is given below. This inequality has many applications; a particularly interesting one is its role in establishing frequentist convergence rates of posterior distributions; this will be outlined in a future post.
increases, this problem intuitively should get easier. Le Cam’s inequality quantifies this by asserting that the error in this hypothesis testing problem decreases exponentially in . The precise statement and a proof sketch of this inequality is given below. This inequality has many applications; a particularly interesting one is its role in establishing frequentist convergence rates of posterior distributions; this will be outlined in a future post.
We first need to specify the notion of error in hypothesis testing. Given a test  (which is simply a
(which is simply a ![{[0, 1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C+1%5D%7D&bg=FFFFFF&fg=000000&s=0&c=20201002) -valued function of the data), its type I error is
-valued function of the data), its type I error is  while its type II error is
while its type II error is 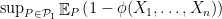 . For ease of notation, let me write
. For ease of notation, let me write 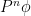 for
for 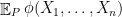 where
where  is the -fold product of with itself. We define the error of a test to be the sum of its type I and type II errors. The smallest error in testing
is the -fold product of with itself. We define the error of a test to be the sum of its type I and type II errors. The smallest error in testing  against
against 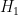 is therefore
is therefore
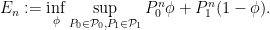
Le Cam’s inequality states that  decreases exponentially in . The rate of this decrease depends on how close the classes and are. This closeness is measured by the so-called Hellinger affinity between and defined as
decreases exponentially in . The rate of this decrease depends on how close the classes and are. This closeness is measured by the so-called Hellinger affinity between and defined as

where  and
and 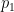 denote the densities of
denote the densities of  and
and  with respect to a common dominating measure
with respect to a common dominating measure  .
.  measures closeness between and with large values indicating closeness. Hence the name affinity.
measures closeness between and with large values indicating closeness. Hence the name affinity.
The precise statement of Le Cam’s inequality is
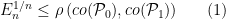
where 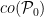 denotes the convex hull of i.e., the class of all finite linear combinations of probability measures in . As a consequence, we have that decreases exponentially in as long as
denotes the convex hull of i.e., the class of all finite linear combinations of probability measures in . As a consequence, we have that decreases exponentially in as long as 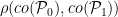 is bounded from above by a constant strictly smaller than one. It must be noted that (1) is a finite sample result i.e., it is allowed that and depend on . It might seem strange that (1) involves the convex hulls of and instead of and themselves. This can be explained perhaps by the simple observation:
is bounded from above by a constant strictly smaller than one. It must be noted that (1) is a finite sample result i.e., it is allowed that and depend on . It might seem strange that (1) involves the convex hulls of and instead of and themselves. This can be explained perhaps by the simple observation: 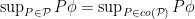 .
.
Let me now provide a sketch of the proof of (1). Let  and similarly define
and similarly define 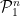 . Rewrite as
. Rewrite as
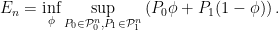
The first idea is to interchange the inf and sup above. This is formally done via a minimax theorem. See this note by David Pollard for a clear exposition of a minimax theorem and its application to this particular example. This gives

Minimax theorems require the domains (on which the inf and sup are taken) to be convex which is why one gets convex hulls above. The advantage of using the minimax theorem is that the infimum above can be easily evaluated explicitly. This is because

We thus get
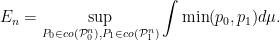
The quantity  also measures closeness between and . It is actually called the total variation affinity between and . The trouble with it is that it is difficult to see how the right hand side above changes with . This is the reason why one switches to Hellinger affinity. The elementary inequality
also measures closeness between and . It is actually called the total variation affinity between and . The trouble with it is that it is difficult to see how the right hand side above changes with . This is the reason why one switches to Hellinger affinity. The elementary inequality 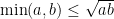 gives
gives

The proof is now completed by showing that
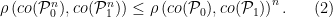
This inequality is a crucial part of the proof. This is the reason why one works with Hellinger affinity as opposed to the total variation affinity although the latter is more directly related to . Let us see why (2) holds when  . The general case can be tackled similarly.
. The general case can be tackled similarly.
Any probability measure in  is of the form
is of the form  for some
for some  . Similarly, any probability measure in
. Similarly, any probability measure in 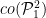 is of the form
is of the form 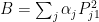 for some
for some 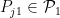 . The Hellinger affinity between
. The Hellinger affinity between  and
and 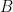 is therefore
is therefore
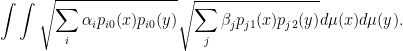
Now if  and
and  , we can rewrite the above as
, we can rewrite the above as
![\displaystyle \int \sqrt{m_0(x)} \sqrt{m_1(x)} \left[ \int \sqrt{\frac{\sum_{i} \alpha_i p_{i0}(x) p_{i0}(y)}{\sum_i \alpha_i p_{i0}(x)}} \sqrt{\frac{\sum_{j} \beta_j p_{j1}(x) p_{j1}(y)}{\sum_j \beta_j p_{j1}(x)}} d\mu(y)\right] d\mu(x).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cint+%5Csqrt%7Bm_0%28x%29%7D+%5Csqrt%7Bm_1%28x%29%7D+%5Cleft%5B+%5Cint+%5Csqrt%7B%5Cfrac%7B%5Csum_%7Bi%7D+%5Calpha_i+p_%7Bi0%7D%28x%29+p_%7Bi0%7D%28y%29%7D%7B%5Csum_i+%5Calpha_i+p_%7Bi0%7D%28x%29%7D%7D+%5Csqrt%7B%5Cfrac%7B%5Csum_%7Bj%7D+%5Cbeta_j+p_%7Bj1%7D%28x%29+p_%7Bj1%7D%28y%29%7D%7B%5Csum_j+%5Cbeta_j+p_%7Bj1%7D%28x%29%7D%7D+d%5Cmu%28y%29%5Cright%5D+d%5Cmu%28x%29.+&bg=FFFFFF&fg=000000&s=0&c=20201002)
Fixing  and looking at the inner integral above, the densities (as functions of
and looking at the inner integral above, the densities (as functions of 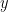 ) involved are all convex combinations of densities in and respectively. Therefore the inner integral above is at most which means that the above quantity is atmost
) involved are all convex combinations of densities in and respectively. Therefore the inner integral above is at most which means that the above quantity is atmost

By the same logic,  . This proves (2) for . The general case is not much more difficult. This completes the sketch of the proof of (1).
. This proves (2) for . The general case is not much more difficult. This completes the sketch of the proof of (1).
References
[1] L. Le Cam. Asymptotic Methods in Statistical Decision Theory. Springer-Verlag, New York, 1986.
Published by Aditya
I am Aditya Guntuboyina. I am an associate professor in the statistics department at UC Berkeley. My current research interests are in nonparametric function estimation, Bayes and empirical Bayes methodology and the theory of empirical processes. This is my research blog. The posts are about random topics in statistics that interest me.
View all posts by Aditya
